Recently I have been playing around with the Quake 1 source, the SDL port [1] to be specific. Quake was released in 1996 by id software as the highly anticipated successor to Doom. It was also the first game of its kind to implement a proper 3d engine, quite a leap from the 2.5d engine of Doom et al.
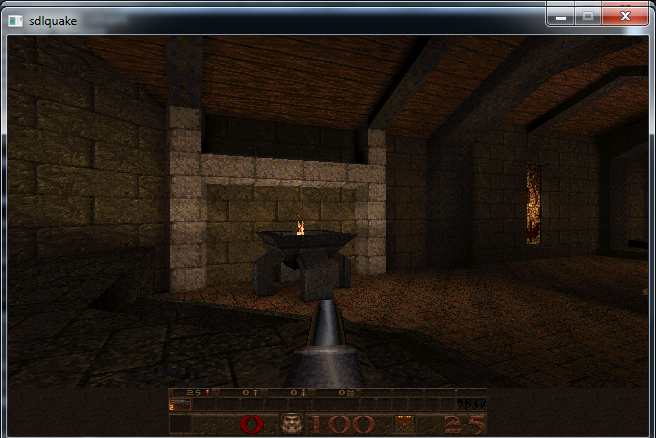
One of the things that interests me about Quake is that it shipped with a highly optimised software rasterizer; and I have a weird facination with software rendering. The quake source also contains a OpenGL rendering system, known as GLQuake, but I dont think the SDL port is quite setup to use it out of the box.
Internaly quake does all of its rasterization using 8 bit palletized colour. While im sure this palette must be part of the games pak data files, it was simple for me to extract the pallette directly from quakes memory, as shown below:

Because each colour is represented as 1 byte, the pallette thus can only contain 256 entries. Each colour entry in the pallete is stored as a RGB triplet, expanding each byte in the colour buffer to 24 bit true colour before its presented on the monitor. The palette setup is done as follows:
// vid_sdl.c
void VID_SetPalette(unsigned char* palette) {
int i;
SDL_Color colors[256];
for (i = 0; i < 256; ++i) {
colors[i].r = *palette++;
colors[i].g = *palette++;
colors[i].b = *palette++;
}
SDL_SetColors(screen, colors, 0, 256);
}
Its clear just by looking at the screen shots that Quake has quite an advanced lighting system for the time, using lightmaps to store all of the incident light at each surface of the world.
Having the source to hand, one of the first things I wanted to do was to disable the surface textures so that I could view just the lightmap by itself. As it turns out this was quite a tricky task, since Quake has to make a few interesting optimizations in this area.
// d_scan.c
// void D_DrawSpans8(espan_t * pspan) {
// ...
do {
*pdest++ = *(pbase + (s >> 16) +
(t >> 16) * cachewidth);
s += sstep;
t += tstep;
} while (--spancount > 0);
Looking at the rasterization code above, which forms the inner loop of the surface rendering, it is apparent that only one texture is being indexed (pbase*), despite it being clear that each surface should be the product of the lightmap and the albido texture. Its also clear in the above code that quake uses 16:16 fixed point arithmetic while indexing the lookup texture.
A little more digging reveales that once a surface has been deemed visible by quakes PVS System [2], it gets cached. During this caching process, a new texture is allocated, which is indeed the product of the lighting contribution and the albido texture.
// r_surf.c
void R_DrawSurfaceBlock8_mip0(void) {
int v, i, b, lightstep, lighttemp, light;
unsigned char pix, *psource, *prowdest;
psource = pbasesource;
prowdest = prowdestbase;
static const int STEPS = 16;
static const int LIGHTMASK = 0xff00;
for (v = 0; v < r_numvblocks; v++) {
// FIXME: make these locals?
// FIXME: use delta rather than both right and left, like ASM?
lightleft = r_lightptr[0];
lightright = r_lightptr[1];
r_lightptr += r_lightwidth;
lightleftstep = (r_lightptr[0] - lightleft) / STEPS;
lightrightstep = (r_lightptr[1] - lightright) / STEPS;
for (i = 0; i < STEPS; i++) {
lighttemp = lightleft - lightright;
lightstep = lighttemp / STEPS;
light = lightright;
for (b = STEPS-1; b >= 0; b--) {
pix = psource[b];
prowdest[b] = ((uint8_t*)vid.colormap)[(light & LIGHTMASK) + pix];
light += lightstep;
}
psource += sourcetstep;
lightright += lightrightstep;
lightleft += lightleftstep;
prowdest += surfrowbytes;
}
if (psource >= r_sourcemax)
psource -= r_stepback;
}
}
The function shown above is responsible for calculating the product of the light and the albido texture and writing that into the cached texture. Looking at the inner most loop reveals that psource is the source texture itself and light is the lighting contribution for this texel. vid.colormap is clearly some kind of lookup table used to combine the two attributes.
To test this out, I set pix to a fixed entry in the quake pallete and fired up the game, to see the following:
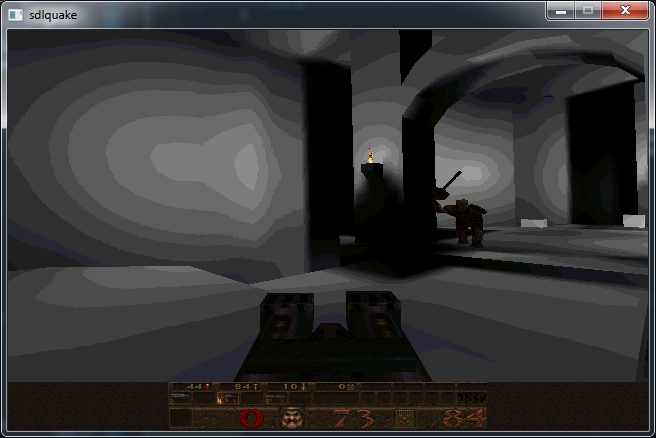
Nice! My hunch that pix was the source texture was correct, and now we are presented with only the lighting contributions. One thing to note is that all dynamic objects in the world still appear textured, and this is because Quake has two rendering pipelines, the one for static BSP geometry that I have been playing around with, and one for dymanic models that I havent delved into yet. That is yet another optimisation.
In order to learn more I dumped vid.colormap and wrote a quick program to transform it by Quakes palette and save it out as the image below:

True to games of that era, its a lookup table containing pre multiplied versions of the base palette. Such and aproach is necessary since we can easily transform from a 8bit colour index to the 24bit colour space that we would need to be in to perform our multiplication with the light, however its not possible to go back from a 24bit colour to the correct 8bit index. By using a pre-multiplied palette we can effectively perform the multiplication, while staying in the 8bit colour index space.
If we instead set light in the above function to zero so that we are always indexing the top row of the colour table, we should render without any lighting contributions.
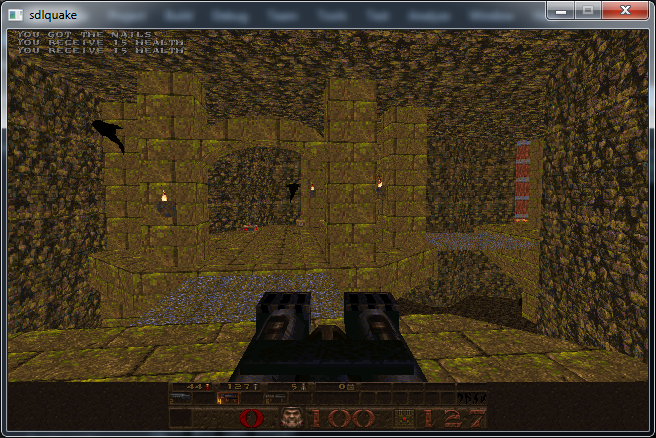
Another interesting point is that Quake also performs Mip Mapping [3], the bennefits of which are two fold. Using smaller textures for far away surfaces reduces memory bandwith and uses less cache while also avoiding visual distortions caused by Alising.
This these changes must be made to each of the following:
// r_surf.c
void R_DrawSurfaceBlock8_mip0(void);
void R_DrawSurfaceBlock8_mip1(void);
void R_DrawSurfaceBlock8_mip2(void);
void R_DrawSurfaceBlock8_mip3(void);
When quake performs its caching, depending on the shape, size and slope of the polygon, one of the above functions will be chosen from a table of function pointers surfmiptable.
// r_surf.c
// void R_DrawSurface(void) {
...
if (r_pixbytes == 1) {
pblockdrawer = surfmiptable[r_drawsurf.surfmip];
...
}
One fun modification that I wanted to make to the rasterizer was to add unreal style filtering [4] to quake, a challenge made more fun because it has to be done using 16:16 fixed point. The block below shows the parts I changed:
// d_scan.c
#define DITHER 1
void D_DrawSpans8(espan_t* pspan) {
// ...
#if (DITHER)
int d_s, d_t;
#endif
// ...
pbase = (unsigned char*)cacheblock;
// ...
do {
pdest = (unsigned char*)((byte*)d_viewbuffer + (screenwidth * pspan->v) + pspan->u);
#if (DITHER)
// dither offsets
d_s = ((pspan->v&1) << 16);
d_t = ((pspan->u&1) << 16) ^ d_s;
#endif
// ...
do {
// calculate s and t at the far end of the span
spancount = (count>=8) ? 8 : count;
count -= spancount;
// ...
do {
#if (DITHER)
// compute dither offsets for texel
int s_offs = (s - d_s + 0x8000);
int t_offs = (t - d_t + 0x8000);
// advance the dither pattern
d_s ^= 0x10000;
#else
int s_offs = s;
int t_offs = t;
#endif
*pdest++ = *(pbase + (s_offs >> 16) +
(t_offs >> 16) * cachewidth);
s += sstep;
t += tstep;
} while (--spancount > 0);
s = snext;
t = tnext;
} while (count > 0);
} while ((pspan = pspan->pnext) != NULL);
}
In the end it looks as follows:
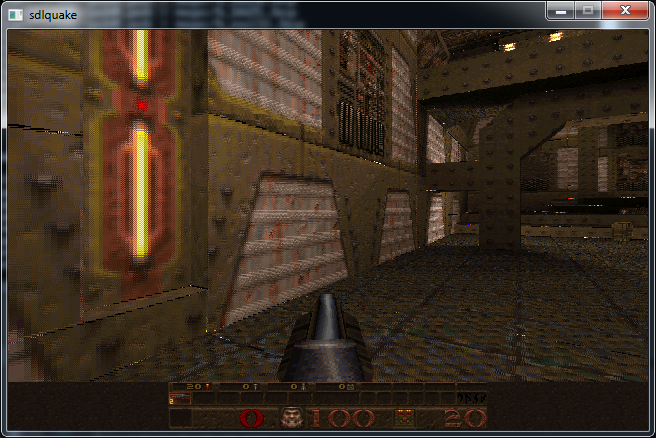
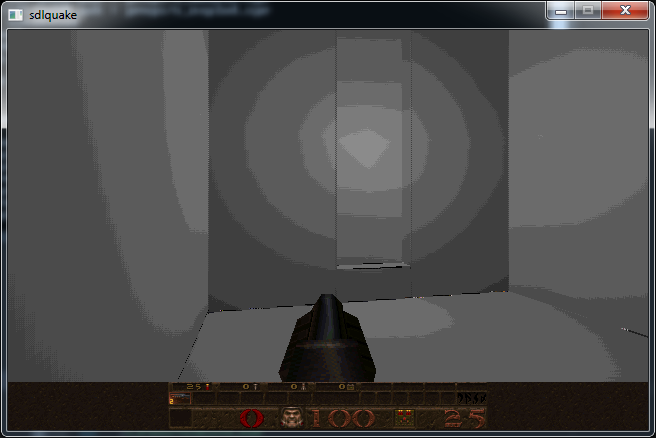
This is a fairly dodgy hack to say the least as you can see we are reading +/-1 texels out of bounds around the edges of each texture. It will require a bit more digging around in the source to correct this problem however.
If any of this was interesting to you, Fabien Sanglard has also written a fantastic teardown of the Quake source code [5]. He also must like the visual aperance of the Unreal texture filter and did something similar for Quake 2, see the end of this page [6]. You can see however that the original flipcode article contains a subtle bug however that is also visible in Fabiend’s screenshots.
The original flipcode article suggests a kernel which adds a small bias to the uv coordinates of half a texel which is undesirable:
(X&1)==0 (X&1==1)
+---------------------------------
(Y&1)==0 | u+=.25,v+=.00 u+=.50,v+=.75
(Y&1)==1 | u+=.75,v+=.50 u+=.00,v+=.25
A kernel such as the following should be roughly equivenant, yet adds no bias:
(X&1)==0 (X&1==1)
+---------------------------------
(Y&1)==0 | u+=.5,v+=.5 u-=.5,v+=.5
(Y&1)==1 | u-=.5,v-=.5 u+=.5,v-=.5
[1] The SDL port was written by Sam Oscar Lantinga, the author or SDL and can be found here: https://www.libsdl.org/projects/quake/
[2] Potential Visibility Set: http://www.phatcode.net/res/224/files/html/ch70/70-02.html
[3] Mip Mapping: https://en.wikipedia.org/wiki/Mipmap
[4] Unreal style filtering: http://www.flipcode.com/archives/Texturing_As_In_Unreal.shtml
[5] Quake source code review: http://fabiensanglard.net/quakeSource/index.php
[6] Quake 2 rendering: http://fabiensanglard.net/quake2/quake2_software_renderer.php